16 Apr 2020

There has been a renewed buzz about monorepos recently.
First of all there was that announcement from Github about git sparse-checkout, an experimental feature in Git 2.25.0 that simplifies the process of partially dowloading a large repository, saving space and improving the performance. I suspect this feature was driven by the growing popularity of of the “microservices in a monorepo”.
Second, the new Software Engineering at Google book was recently released and it often references both the benefits and disadvantages to monorepos.
Over the last couple of years I experienced projects where monorepos organically came into being or were explicitly selected for. Similarly to many others out there I came to the same conclusions in terms of their advantages:
- Sharing dependencies, means managing less - if several services depend on eachother but are in the same repository you have the same version number so it’s less likely to encounter issues.
- No more cross-repo changes - many features I’ve had to implement, crossed service boundries and would require additional steps (cloning, checkingout, switching contexts), but with a monorepo it’s all in one place so you could make the change in a single commit.
- Seeing the bigger picture - if services from the same domain are centralised in a monorepo it’s much easier for someone to understand how they are related, rather than doing haphazard Github searches.
References:
- https://danluu.com/monorepo/
- https://research.google/pubs/pub45424/
- https://medium.com/@chrisnager/case-for-a-monorepo-28cebf26e1aa
image by Owen Davey
13 Apr 2020

So today is Easter Sunday and we are still on lockdown.
I could have spent the weekend building an API client, polishing my CV or make progress on the 30-day LeetCode challenge.
Instead I decided to go for my government-sanctioned walk.
Going for these long walks by myself can get a bit monotonous, so I wanted to listen to an audiobook. However, the issue was that I had an mp3 file that was 12 hours of continuous audio. I had never bothered to understand why my iOS Music app or iTunes couldn’t remember the current position once I paused or stopped it so I decided to apply some “engineering thinking” to this problem. I had come up with two initial approaches which I cross-validated with Reddit.
Estimation approach
The first one involved finding the table of contents for the book and getting a sense for how many pages each chapter is.
Then assuming an average narration speed of about 2 minutes I could get the timings for each chapter.
I could then skip to each part and use Audacity, QuickTime or iTunes to split the file into parts.
After spending about 5 to 10 minutes on finding the table of contents and failing I decided to go with my second approach.
AI approach
This second approach involved finding a library on Github which would help me analyse audio files for occurrences of specific words.
After a few minutes of searching, I discovered SpeechRecognition. It was essentially an interface for many different audio processing APIs. The only offline API was provided by a library developed at Carnegie Mellon University called CMUSphinx. According to their blog it has been superseded by BERT, Wavenet and others. I chose to use it as it was way simpler at first glance.
After some further Googling and going on StackOverflow I had my process down:
- I would convert the into a 16khz mono file to enable processing
ffmpeg -i file.mp3 -ar 16000 -ac 1 file.wav
- I would build and install the latest version of the a lightweight recognizer library written in C called
pocketsphinx library.
brew tap watsonbox/cmu-sphinx
brew install --HEAD watsonbox/cmu-sphinx/cmu-pocketsphinx
If you’re on a Mac using Homebrew should work without any hiccups. The alternative is to try to compile the library from source, which can be a bit more painful as there are all of these transative dependencies and you have to make sure the directory where you cloned the library is called pocketsphinx.
- Download the latest modified language model in my case for US English.
- The run the detection
pocketsphinx_continuous -infile file.wav -hmm ~/Downloads/en-us -kws_threshold 1e-10 -keyphrase "chapter" -time yes
Here is an overview of the flags:
-infile Audio file to transcribe.
-hmm Directory containing acoustic model files.
-kws_threshold Threshold for p(hyp)/p(alternatives) ratio
-keyphrase Keyphrase to spot
-time Print word times in file transcription.
After finally congfiguring everything, I ran the model it wasn’t as accurate as I hoped. Realised it would have taken at least 40 minutes to complete it was time to abandon this approach. It was a good learning experience!
Okay so I still hadn’t partitioned this large mp3 into smaller more managable pieces. It was time to use QuickTime and simply trim the audio to my liking!
QuickTrim approach
Simply open the file in QuickTime Player or any audio editor.
In QuickTime Edit > Trim opens the editor menu as seen below
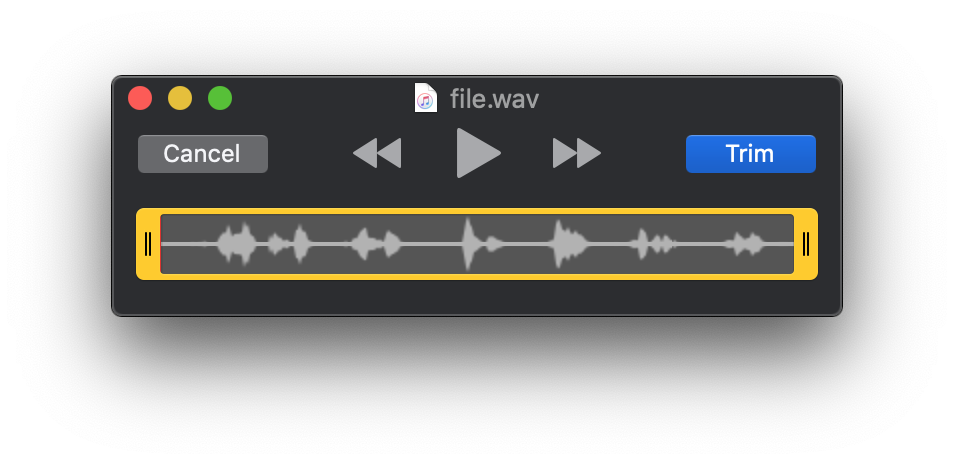
All you need to do is spot the pauses and trim up to that point.
It’s not perfect but you would end up with smaller pieces of content that you can consume in one session.
Obvious approach
What I could have done from the start is simply Google for my issue.
I would have quickly discovered that there is an option to persist the last playback position.
While playing the audiobook simply select Edit/Song Info/Options>Remember Playback Position (and tick the box).
12 Apr 2020
As software engineers our environment is ever changing. Things are moving fast. “Once in a lifetime” events seem to happen every couple of years now. That’s why I think one needs to stay sharp and interview at regular intervals.
- Otta - my personal favourite. Great companies, great UI/UX, well curated content.
- Hired - if you’re looking for startups and FANG companies you’ve already heard of them. The model here is companies reach out to you.
- StackOverflow Jobs - I haven’t extensively used it but I think any self-respecting engineering org should post their jobs on here as well.
- TripleByte - only available in the US. But you can still take the quiz! Somehow I was in the 83 percentile when I did it. I must be good at guessing.
Coding prep:
- LeetCode - loads of problem sets and active community. Read about it on Quora.
- HackerRank - I think it has more practice questions than LeetCode but it’s not the community favourite.
- AlgoExpert - if you’ve been on YouTube for any period of time you must have seen the adverts.
- Codeforces - if you’re hardcore and serious about the coding challenges you do.
- CodeChef - haven’t personaly used it but it’s questions can get repetative.
- Geektastic - It’s not as slick as everything else but some companies use it so you might as well familiarise yourself. If you use this link you will get 50% your first 3 months.
Coferences:
This will sort of depend on your specialisation. Also they can get quite pricey so if you’d like to attend just volunteer! Here are the ones I like:
- PyCon - I’ve attended the UK one, but the one in the US is much bigger.
- goto; - volunteered for this one a couple of years ago, it was great!
- QCon - another massive conference, which I volunteered for.
Books and blogs:
YouTube:
I love spending my time on Youtube, that’s how I get most of my information these days. But it’s very important that you actually do prep questions rather that watch these videos for hours (speaking from experience).
- Joma Tech - very entertaining and informative
- TechLead - I used to love his content now I’m a bit more wary of it.
- Gaurav Sen - outstanding videos on interview prep and system design. The images in this post are from his video.
- Clément Mihailescu (AlgoExpert) - his content is also quite good but I’ve got brand loyalty to Joma and TechLead, they can be a bit more entertaining.
- CS Dojo - haven’t watched his content in a while but he’s got some solid explanation videos. Most everyone else has put their explanations behind a paywall.
10 Apr 2020
Not too long ago I was tasked with looking into a performance issue with an internal service using Redis.
At the time I had no exposure to it after some time I identified that the issue might be related to issues with key expiration. As part of my investigation I found this great talk by @antirez, the creator of Redis, on The Evolution of Redis Key Expiration Algorithms. This is a short post about my learnings, with links to relevant points in the C code.

Intro
Let’s start with the basics, Redis stands for Remote Dictionary Server, as the name suggests it is a distributed, in-memory key-value database. It uses a hash table, called dict as it’s core data structure, where values can be stored as a linked list.
One of the many features it provides is EXPIRE, which sets a timeout for a given key. In other words it allows users to specify how long the keys shoul exist for before being delete.
In order to make this happen Redis needs to store the expiration information with a key.
The obvious approach is to have the existing data structure support expiry for each key. However, this adds unnecessary memory overhead, if only a small subset of keys are set to expire.
The alternative solution is to have a second hash-table that stores the expiry information. The image below attempts to illustrate this.
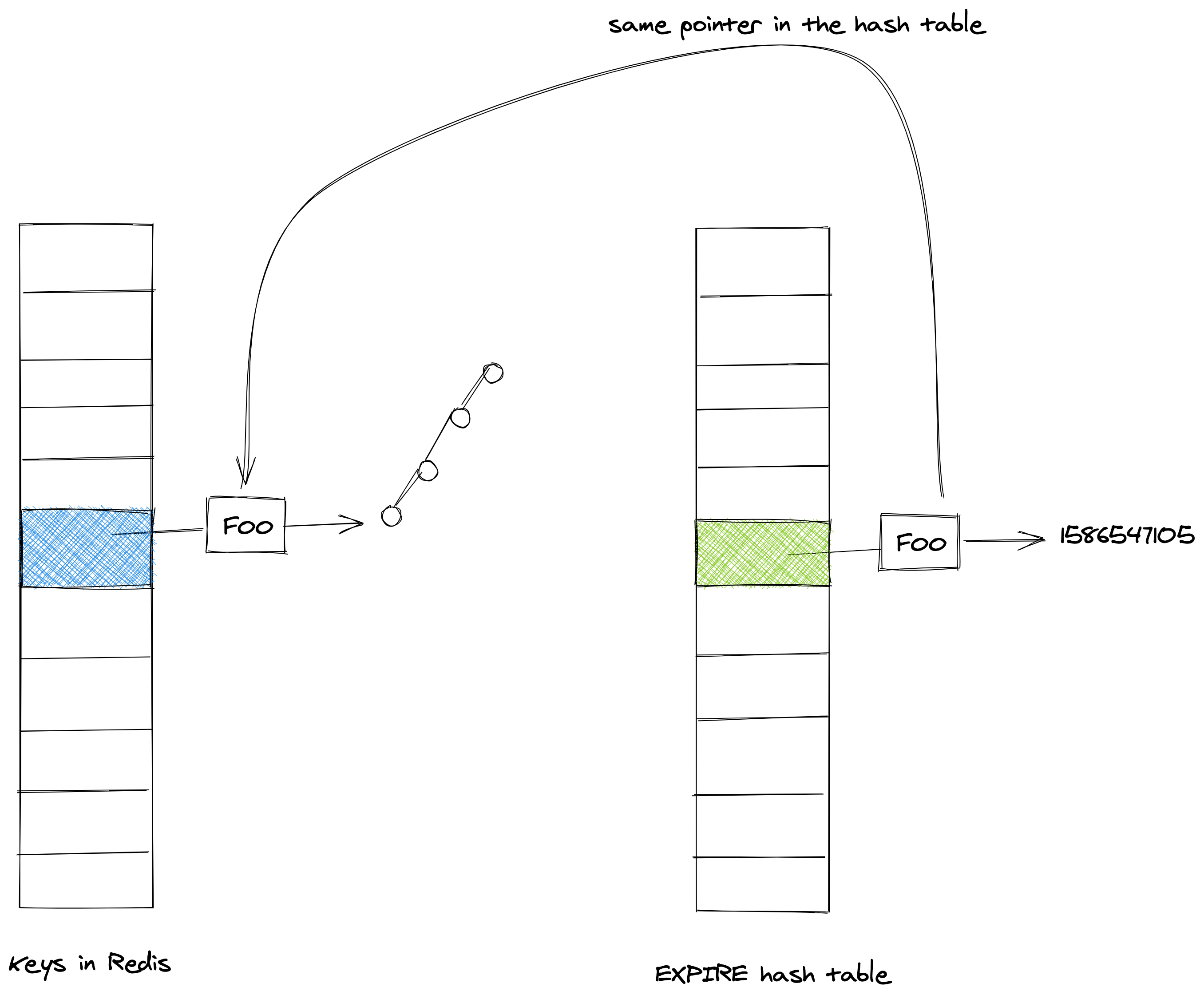
The time at which a key will expire is set at a unix timestamp.
To further conserve space, Redis reuses the pointer for the key from the primary dict, in terms of the expiry, the author also tries to optimize by storing a unix timestamp as a pointer.
To conserve space it gets stored as a pointer.
This means that if there are no expires, the expiration hastable is empty.
- The keys are shared so there is no waisted memory
- The expiration information gets stored in place of the pointer for the value object in the hashtable
How to evict keys:
- Passive expiration
- If Redis receives the command
GET('foo')
- Down the call chain it calls
lookUpKey
- This in turn calls
expireIfNeeded which ensures that if the time has passed the key expires
- It returns a
NULL to the caller if has expired
- Active expiration
In the second approach we apply random sampling to the expires table.
We sample 10 times per second and test 20 random keys. If the expire time is less than the current timestamp i can evict the key.
However as the number of keys to be expired becomes smaller we are simply burning CPU.
The less keys are expired the more CPU we burn.
After we find less than given percentage of keys that are expired we stop the expire cycle. In the case of Redis this is 25%
When Twitter upgraded from v2.8 (quite an old version) to v6.0 they noticed a regression.
In their case where 25% of keys that were expired was not an acceptable default.
That’s why an effort configuration was introduced
New approach
Using a Radix tree
Some people have a usecase where they want to use Redis as a timer.
What they would do is listen to the Keyspace notification for expired events
Redis docs:
Specifically this is what Redis does 10 times per second:
- Test 20 random keys from the set of keys with an associated expire.
- Delete all the keys found expired.
- If more than 25% of keys were expired, start again from step 1.
However imagine you have a million keys that are “forgotten” by the application code.
That means they won’t be accessed therefore never expired if we only relied on this approach.
To check for an expire he checks the “expire hashtable” for a an entry with that key
KeyDB - Rethinking the Redis Key EXPIRE
CubeDrone Endiannes
https://redis.io/commands/expire
https://github.com/antirez/redis/blob/b73d87f5e59ae68a2b901fe5a158d6e22840214c/src/expire.c#L123
07 Apr 2020

Sometime ago I watched a talk on People First Engineering Management @ Monzo.
It’s full of really interesting and insightful content but my biggest takeaway was the following the tech lead anti-patterns.
Let’s use Monzo’s definition of a Tech lead first:
- A fairly experienced engineer
- Who is still working as an individual contributor and writing code.
- And wears a hat 👒 (this is not a role or a progression level)
They are expected to:
- Pair with the product manager on the squad’s success
- Provide technical context and direction
- Enable and empower other engineers
- Foster effective collaboration
- Won’t necessarily be a tech lead forever
Now that we have this in mind here are the anti-patterns:
- The Faux PM 👩🏻🏫
- Tries to get involved by prioritising the backlog
- Doing their own research
- Writing their own tickets (team’s tickets)
- Finding features on their own
- The Dictator 👮🏻♂️
- This is where they define the scope of the project and hand it off to somebody else
- Over specifying and not doing any implementation themselves
- Only ever doing the most interesting work
- The Martyr 🧝🏻♀️
- Tries to do everything, all the small and boring tasks
- Working late, trying to save the day, so no one else has to
- Not knowing when to delegate
- The Over-Empathiser 👩🏽⚕️
- Not giving constructive feedback
- Not holding people to account
- Fixing other people’s code themselves